The LLM market is characterized by a high degree of complexity and rapid innovation. With the availability of numerous models, each boasting distinct capabilities, organizations face significant challenges in selecting the most suitable LLM for their specific use cases.
The opaque nature of the training data used in proprietary models further complicates this process, making it difficult to fully understand their behaviours and potential risks. Additionally, traditional validation methods often fall short against the scale and complexity of modern LLMs, leading to potential issues in scalability and generalization.
The need for a structured and rigorous benchmarking process is increasingly pressing, not only to minimise the risk of deploying suboptimal models but also to ensure compliance with evolving regulatory standards and ethical guidelines, ultimately building trust with stakeholders and driving innovation.
The Different Stages of LLM Validation
Effective LLM validation is not a one-size-fits-all process but rather a multi-faceted approach that requires careful consideration at each stage.
As part of the full mode life cycle, after clearly defining the objectives and metrics that align with the intended use case (a crucial step setting the foundation for all subsequent evaluations) and preparing and cleaning the data, evaluation can be viewed as belonging to the following four major areas.
Quantitative Evaluation – Quantitative metrics are employed to evaluate the model's performance. These metrics are task-specific and provide objective measures of how well the model is performing. While traditional classification metrics like accuracy, precision, and F1 score are useful for some tasks, LLMs often require more nuanced and task-specific metrics such as Rouge for summarization and text generation
Qualitative Evaluation – Human evaluation plays a significant role in assessing the quality, coherence, and relevance of the model’s outputs. This stage helps identify areas where the model may perform well on paper but falls short in real-world applications.
Robustness Testing – The model is tested against various adversarial inputs to assess its stability and security, identifying potential vulnerabilities that could be exploited in real-world scenarios, such as jailbreaking and prompt injection.
Bias and Fairness Testing – Finally, the model's outputs are examined for bias and fairness, ensuring that the LLM treats all demographics equitably and adheres to ethical standards. This stage is particularly important in applications where decisions can significantly impact people's lives
Each stage of validation is necessary for the overall success of deploying LLMs, ensuring that the models not only perform well but also operate within ethical and secure boundaries. Although each stage demands investment of resource, effort, and expertise, omitting any one of them could lead to gaps that surface in production or can be exploited by malicious parties.
1. Quantitative metrics
Quantitative metrics form the starting of LLM evaluation, offering objective measures that help quantify a model’s performance across different tasks. These metrics are tailored to the specific tasks that LLMs are designed to perform, ranging from language modelling and text generation to machine translation and summarization. Industry benchmarks (such as HuggingFace’s LLM Leaderboard) can be useful for determining a shortlist of models and providers from the market that you may want to test for your use case. Figure 1 shows examples of quantitative metrics by task.
Figure 1: Non-exhaustive list of quantitative metrics for LLMs, grouped by task
Depending on your use case, you might consider LLM performance in the following areas:
While quantitative metrics provide a robust framework for evaluating LLMs, they must be interpreted carefully, especially in the context of the specific use case. Published metrics often highlight strengths that may not fully align with the practical needs of an application, necessitating a more nuanced approach to their application.
Figure 2: BLEU Summarisation Scores of LLMs Llama3 (Meta), Gemma2 (Google), ChatGPT4o (OpenAI), and Luhn Summarisation Algorithm on BCBS 239 documentation, assessed across a range of uni-, bi-, tri- and quad-gram overlap weightings
For example, if you need an LLM to summarise text on BCBS documentation, you may choose Llama3 as it displays better overlap between the summarised and original text, as seen in Figure 2. However, if you wanted a summarisation that delineated different topics within the original text, ChatGPT-4o could be better – something we will examine in a future article.
Once you have shortlisted models to build into your pipeline, it is prudent to evaluate them using metrics that are bespoke to your use case and KPIs and tested on your data. For example, evaluating a model's suitability for finance and banking involves assessing its pre-training on financial texts, ease of fine-tuning with domain-specific data, and ability to transfer knowledge from general language tasks to finance-specific applications. This ensures the model performs well in the unique context of the financial sector.
2. Qualitative Metrics
While quantitative metrics provide numerical insights into an LLM’s performance, qualitative metrics capture the nuances that numbers alone cannot. These human-centric evaluations are useful for validating how well an LLM performs in real-world scenarios, where the subtleties of language, context, and user interaction play significant roles.
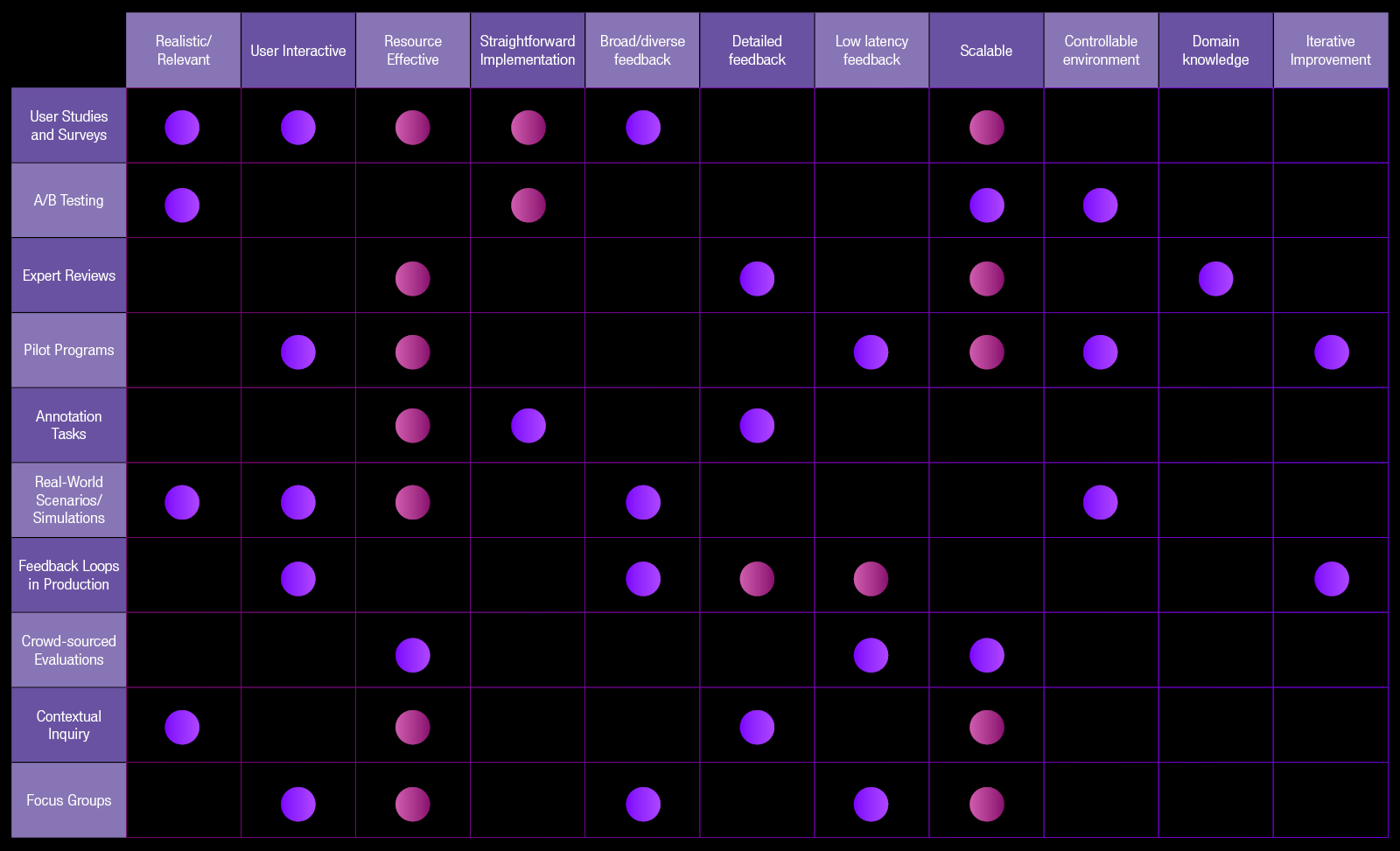
Human-in-the-loop (HITL) evaluation approaches can enable continued SME involvement to understand model idiosyncrasies, mitigate risks and improve fidelity in a controlled environment before the model is deployed to production. Due to resource requirements (financial and FTE), this step could easily be omitted during prototyping but should be deeply considered before deployment, and should heavily involve business stakeholders to weigh against budget and timelines.
Figure 3: Summary of HITL approaches with qualitative assessment of strengths; green denotes a strength of the approach, orange denotes an area to consider when employing the approach
3. Robustness Tests
As LLMs become more integral to various applications, their vulnerabilities also become more apparent. These vulnerabilities can be exploited by adversarial attacks, involving deliberately crafted inputs designed to trick the model into producing incorrect or harmful outputs. Addressing these vulnerabilities through robust defences is critical to ensuring the safe deployment of LLMs.
Combating adversarial attacks can be a hugely laborious task, and it is reasonable that enterprise users of the LLMs expect the heavy lifting to be done by the providers. Nevertheless, providers can only do so much, so it is prudent to consider the defensive strategies that tech teams can incorporate into their processes:
4. Bias & Fairness
Ensuring that LLMs operate fairly across all demographic groups is a core principle of Responsible AI. Bias in the data that LLMs train on can lead to unequal treatment of users, perpetuating stereotypes and potentially causing harm in decision-making processes.
Bias and fairness testing for LLMs focuses on evaluating model outputs across diverse demographic groups and contexts to identify disparities. It involves tasks like language generation, sentiment analysis, and classification, using diverse datasets and specific metrics to assess and ensure fairness and equity in model performance. The tests broadly cover the following approaches:
Ensuring fairness in LLMs involves not only using diverse datasets and benchmarks but also continuously monitoring and updating the models to address emerging biases. While these tests primarily serve to diagnose biases, mitigating them is an integrated process where techniques such as prompt engineering can provide guardrails for the LLM when generating responses. However, total protection is not guaranteed, and periodic review of the outputs and user feedback is required to ensure users are treated fairly.
Beyond Model Performance: Cost
A final, but important factor, is the cost of running your use case leveraging a certain model. LLMs costs can vary significantly based on several factors, including the type of model, its size, usage frequency, deployment environment, and the provider's pricing structure.
There are scenarios where there can be up to a 20 x price variance between different models for the same use case. This is critical for business to consider alongside performance to ensure the solution is viable and allows for business value to be generated.
Conclusion
Benchmarking LLMs is a complex yet essential process that goes beyond mere performance evaluation. It encompasses a comprehensive assessment of quantitative and qualitative metrics, robustness, and ethical considerations such as bias and fairness.
As LLMs continue to evolve and become integral to various applications, it is imperative for organizations to adopt a rigorous benchmarking framework. This framework ensures that the models not only perform optimally but also operate within ethical and secure boundaries, ultimately leading to more reliable and trustworthy AI systems.